
When you think of the perfect start to your Natural Language Processing (NLP) journey, are you considering beginning with popular techniques like Word2Vec, ELMo, BERT or Transformers? Well this does sound inspiring and must have sparked an interest to open your Jupyter notebook and begin coding, but it might not be the first thing to get started with on your NLP journey.
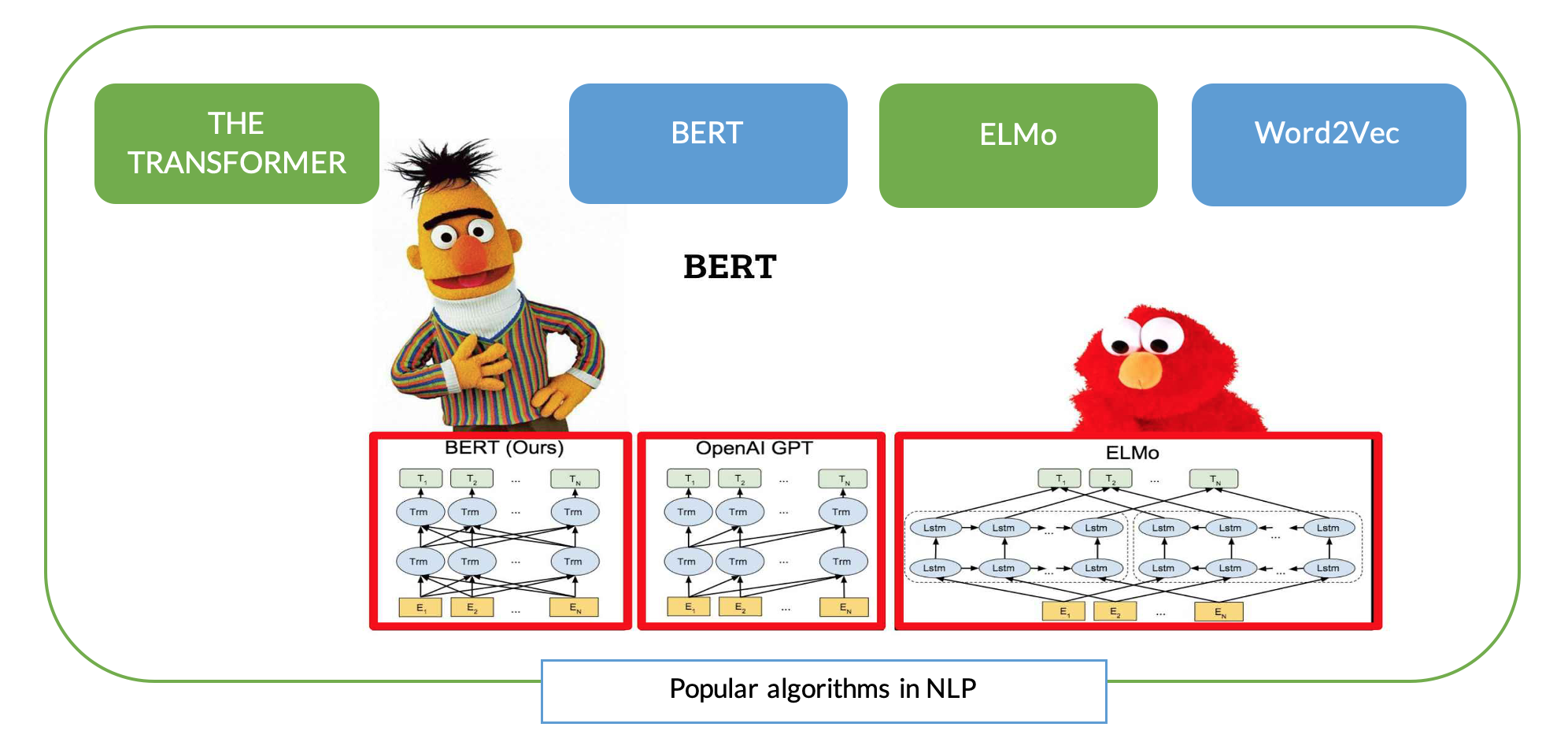
What is Natural Language Processing?
Natural Language Processing is a subset of the Artificial Intelligence domain that enables computers to understand, interpret, and use human language. It is a tool that helps us build intelligence and drive insights from human language (most commonly text data).

History of Natural Language Processing
In 1950, Alan Turing wrote a paper describing a test for a “thinking” machine. He stated that if a machine could be part of a conversation using a teleprinter, and it imitated a human so completely that there are no noticeable differences, then the machine could be considered capable of thinking. Shortly after this, in 1952, the Hodgkin-Huxley model showed how the brain uses neurons in forming an electrical network. These events helped inspire the idea of Artificial Intelligence (AI), Natural Language Processing (NLP), and the evolution of computers.
NLP was not born overnight, it has evolved as time and technology advanced and continues to evolve today. The below diagram highlights some of the significant algorithms created along the NLP journey.
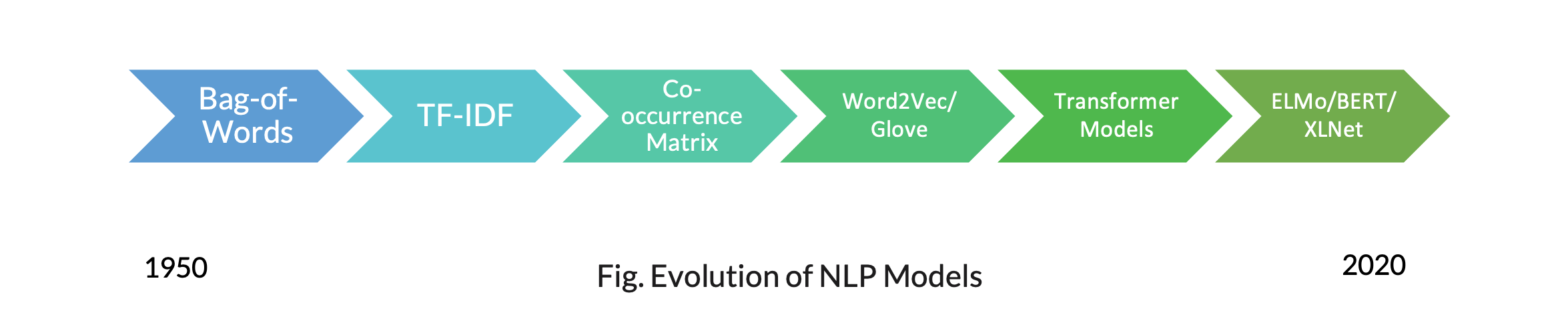
NLP started with very simple models like the Bag-of-Words model which simply counts the occurrence of each word within a document. However, real world applications have corpuses of millions of documents which may have millions of unique words within them. It became difficult to represent the count of each word in such a large matrix, and if you haven’t tried it, the results are quickly dominated by common words such as “is”, “a”, “the”, etc. This led to the introduction of another technique called TF-IDF which eliminated the common words or “stop words”. As these techniques did not include semantic relationships between words, another advanced technique, Co-occurrence Matrix, was created. This technique generated word embeddings to track the sentiment or the context of the text. Co-occurrence matrices required a large amount of memory to store the resulting matrix, which eventually led to other more advanced techniques involving neural networks.
Word2Vec was among the first prediction-based modeling techniques in NLP. It included techniques which are frequently used today such as Skip Gram and Continuous Bag of Words. These techniques leverage neural networks as their foundation and consider the semantics of the text. They also use a FastText algorithm (developed by Facebook), that uses character level information to generate the text representation. The word is considered as a bag of character n-grams in addition to the word itself.
ELMo came into existence with a key idea of solving the problem of homonyms in word representation. Take these sentences for example, #1, “I like to play cricket” and #2, “I am watching the Julius Cesar play”. The word ‘play’ has different meanings.
Along with these developments, also came the Transformer Models in the form of encoders and decoders. It is a model that uses attention to boost the speed of training and outperformed the Google Neural Machine Translation model in specific tasks. Similarly, BERT (Bidirectional Encoder Representations from Transformers) uses encoder representations of the transformer network and has marked a new era in NLP by breaking several records in handling language-based tasks.
Recently, researchers from Carnegie Mellon & Google developed an Attention Network based architecture called the XLNet. Published in 2019, it claims to outperform BERT in 20 different tasks. At the same time, a Chinese company published another Attention Network based model called ERNIE 2.0, they claim to outperform both BERT and XLNet in 16 different tasks.
Ok, so now you are probably even more excited, right? Well, wait just a minute…. before you get too excited, it is important to build a strong foundation in NLP first. To do so, it is important to start your NLP journey with some of these important building blocks:
- Linear Algebra – this is a mathematical component required to build a strong base in visualizing the conversion of text to machine understandable format. It helps to correlate how each feature contributes to dimensions used in text representation.
- Token Representation (Frequency Based) – a way to represent a token that can be interpreted by the machine. This transformation could include various dimensions of the text like syntactic, semantic, linguistic, morphological, etc. To ease your journey, it is recommended to start with frequency-based techniques like Bag of words or TF-IDF and then move to semantic based representation and so on.
- Neural Networks – these are the connection between neurons present in different layers that help a machine learn some rules based on the input and output data. They are used as building blocks in many state-of-the-art modeling techniques in NLP, hence it is vital to understand the working of neural networks and their different variants.
- Transfer Learning – it is a technique that utilizes the learnings (can be informed of weights or embeddings) from other systems or models. It has proved to be valuable in solving many problems, since you carry forward the learnings and helps to reach an optimum solution in optimal time.
How to apply NLP in practical arena
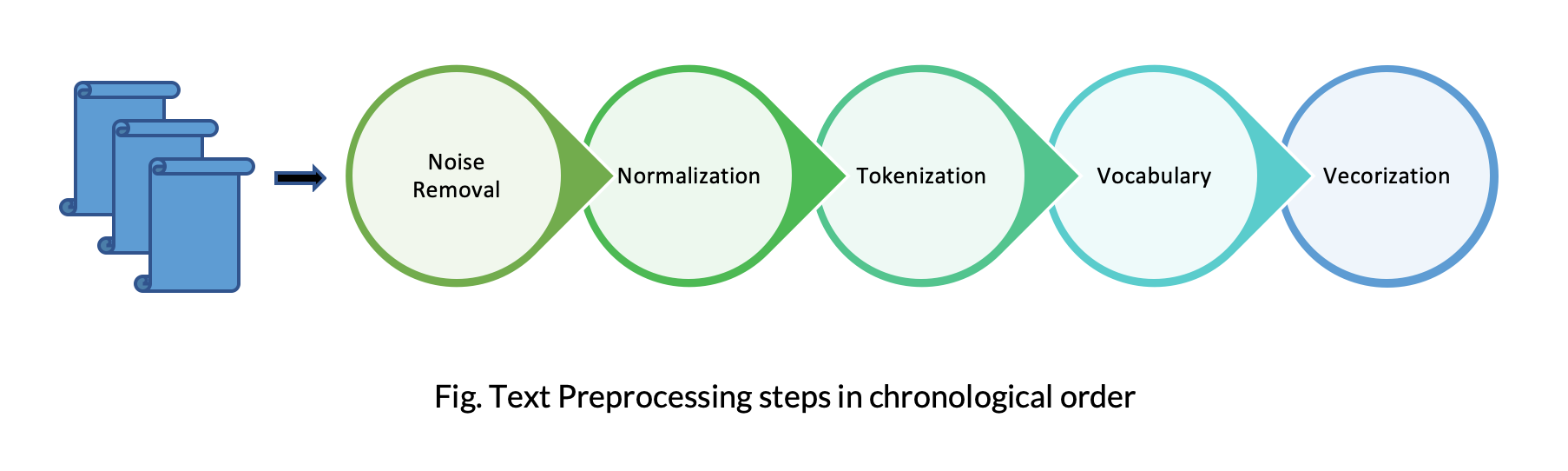
We saw a brief history of the models used to perform NLP tasks but hold on, what steps do we need to follow for any NLP task? And how do we choose one of the above-mentioned NLP algorithms to generate vectors? Well, we cannot just feed in text data to the machines. It needs to be processed first even before converting to vector format and here, text pre-processing comes in handy.
Text pre-processing involves the steps performed in transforming the data prior to feeding it into the machine and is important in a lot of ways. Let us understand this with an example of Sentiment Analysis on one of the customer reviews taken from Yelp.
Sentiment analysis is an NLP task that involves analyzing text and extracting sentiment (i.e. whether the text is with positive, negative, or neutral sentiment). Some of the pre-processing steps involve removing common words and numeric values as they do not contribute much to the sentiment of a text. These pre-processing steps usually improve the accuracy of the sentiment analysis. For instance, say we extract customer reviews from Yelp and we get a review like “We ordered 2 burgers, they were amazing!”. After applying pre-processing steps, the text becomes “ordered burger amazing” and the algorithm running the sentiment analysis is more likely to produce better results.
Some of the steps involved in processing text are:
- Noise Removal
- Normalization
- Tokenization
- Vocabulary
- Vectorization
Noise Removal
- Remove whitespaces
- Remove HTML tags
- Convert accented characters
- Remove special characters
- Remove words
- Remove stop words
Normalization
- Lowercasing characters
- Expand Contractions
- Numeric words to numbers
- Stemming / Lemmatization
Tokenization
Vocabulary
- Remove duplicate words
- Build Vocabulary
Vectorization
Once you have the pre-processing steps done, you are ready to begin building foundational NLP models.
Word Embeddings (Vectorization)
In very simplistic terms, Word Embeddings are representations of text in the form of numbers, also called vector representations. There can be different numerical representations of the same text.
Many machine learning algorithms and almost all deep learning architectures are incapable of processing strings or plain text in their raw form. They require numbers to perform any sort of job, be it classification, regression etc. in broad terms.
At a high level, the word embeddings can be classified into two categories –
- Frequency Based Embedding – considers the frequency as the basic metric
- Prediction Based Embedding – considers the semantics and frequency as the metric
Frequency Based Embedding
- Bag of Words (also known as Count Vectors)
Consider the two sentences are in a separate document
Doc1 (D1) ->Jane is a smart person. She is always happy.
Doc2 (D2) ->John is a good photographer.To find word embeddings through count vector, we will find the unique tokens here (N) and the number of documents(D). The resulting count vector matrix will have dimensions D x N.It will be represented as:
|
Jane |
is |
a |
smart |
person |
She |
always |
happy |
John |
good |
photographer |
| D1 |
1 |
2 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
| D2 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
- TF-IDF
TF stands for Term FrequencyTF is calculated as (number of times term t appears in the document) / (number of terms in the document)It basically denotes the contribution of words to the documentIDF stands for Inverse Document Frequency. IDF is calculated as log(N/n), where N is the number of documents and n is the number of documents a term t has appeared in.
- Let us understand this with an example: Doc1 – Sachin is a cricket player. Doc2 – Federer is a tennis player.
| Doc 1 |
Doc 2 |
| Sachin |
Federer |
| is |
is |
| a |
a |
| cricket |
tennis |
| player |
player |
- TF of D1 and D2 = 1/5IDF for ‘Sachin’ = log(2/1)= 0.301IDF for ‘a’ = log(2/2) = 0TF-IDF for ‘Sachin’ in D1 = (1/5) * 0.301 = 0.602TF-IDF for ‘a’ in D1 = (1/5) * 0 = 0
Prediction Based Embedding
- Skip – Gram
Skip-gram is one of the learning techniques used to find the most related words for a given word. The main objective of Skip Gram is to predict the context when given a word. It also contains the window size similar to co-occurrence matrix. The skip-gram model is basically a neutral network in its simplest form.
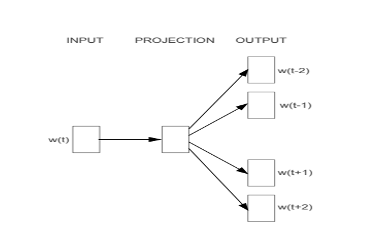
Skip-Gram Architecture
- As we can see w(t) is the target word or input given.
- There is one hidden layer which performs the dot product between the weight matrix and the input vector w(t).
- No activation function is used in the hidden layer. Now the result of the dot product at the hidden layer is passed to the output layer.
- Output layer computes the dot product between the output vector of the hidden layer and the weight matrix of the output layer.
- Then apply the SoftMax activation function to compute the probability of words appearing to be in the context of w(t) at given context location.
Example: Covid-19 is short form for coronavirus disease 2019. (window size=2 )
We are going to train the neural network to do the following. Given a specific word in the middle of a sentence (the input word), look at the words nearby and pick one at random. The network is going to tell us the probability for every word in our vocabulary of being the “nearby word” that we chose.
| Covid-19 |
Is |
short |
form |
For |
coronavirus |
disease |
2019 |
Training samples- (short, Covid-19), (short, is), (short, form), (short, for)
| Covid-19 |
Is |
short |
form |
For |
coronavirus |
disease |
2019 |
Training samples- (form, is), (form, short), (form, for), (form, coronavirus)
We are going to represent an input word like “short” as a one-hot vector. This vector will have as many components as in our vocabulary and we will place “1” in the position corresponding to the words “short”. Example: “short” will be 00100000.
The hidden layer is going to be represented by a weight matrix with the dimension (vocabulary size x number of hidden neurons). Example- (8×300).
The output of the network is a single vector containing for every word in our vocabulary, the probability that a randomly selected nearby word is that vocabulary word.
Conclusion
There are many exciting applications using NLP and machine learning like Sentiment Analysis, Information Extraction, Language Translation, Chatbots, Speech Recognition, etc. In almost all the applications, the state-of-the-art technique is achieved using advanced techniques like Sequence Modeling using Transformers, ELMo or BERT.
As a new user you might get lost in understanding these advanced concepts therefore it is critical to begin your NLP journey with building blocks like Linear Algebra & Differential Calculus, Bag of words, TF-IDF, and the basics of Neural Networks. Thankfully, in the digital age, you can gain an understanding of how to apply these algorithms from online education sites like Udemy, Coursera, etc. Once you’ve built that understanding, you can quickly begin advancing both your NLP models and results using the open research published by titans like Google & CMU and employ your favorite Sesame Street characters (BerT, Ernie, Elmo).

Leave a Reply